Ich habe vor einigen Tagen einen Newsletter bekommen, in dem eine Firma ihre automatisierte Texterkennung anpreist, die nun – dank Machine Learning – „mit jedem Dokument besser“ wird. Die automatisierte Texterkennung ist in einer Welt der In-App-Purchases keine automatische Verbesserung eines Service, für den man als Kunde schon länger bezahlt, sondern ein kostenpflichtiges Zusatzmodul. Aus Sicht des Kunden stellt sich mir allerdings die folgende Frage: Wofür bezahle ich eigentlich, wenn von einem Modul, das sich mittels Machine Learning ständig verbessert, die Rede ist? Um diese Frage beantworten zu können, muss man wissen, wie Machine Learning funktioniert.
Stark vereinfacht basiert Machine Learning auf dem kontinuierlichen Training von Programmen, die Gruppierungen und Strukturen (z.B. Buchstaben und Wörter) in einem spezifischen Set von Daten (wie eben eingescannten Dokumenten) immer besser und immer zuverlässiger erkennen können. Dass diese Programme geschrieben werden müssen und dass dafür zu bezahlen ist, steht außer Frage. Wie sieht es aber mit der Funktionalität der im Newsletter angepriesenen „Texterkennung“ aus? Kann sie auf nur die Programmierleistung beschränkt werden? Immerhin besteht sie eben nicht nur aus der einmaligen Programmierung eines maschinenlernfähigen Texterkennungsmoduls, sondern setzt sich aus mehreren Teilen zusammen, wobei einer davon – das für den Erfolg entscheidende Training des Moduls mit Echtdaten – nicht vom Anbieter erbracht wird, sondern von mir, dem Nutzer.
Was passiert also? Der Anbieter schafft ein lernfähiges Programm, welches aus den Eingaben und Korrekturen seiner Nutzer lernt. Die Leistung der Nutzer wird damit meiner Meinung nach zu einem Bestandteil des Produkts, denn ohne sie ist das Produkt funktionsunfähig und damit sinnlos. Wenn aber eine Technologie ohne meine Trainingsdaten nicht in ein Produkt aufgehen kann, ist dann meine Trainingsleistung als Arbeit zu verstehen, die ich für die Entwicklung dieses Produkts kostenlos verrichte? Ich denke schon.
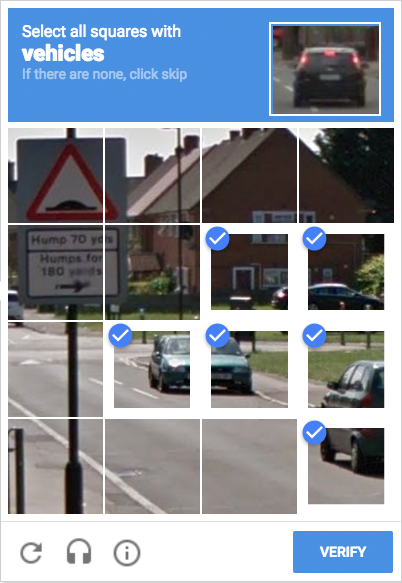
Sieht man sich das Modell hinter dem Terminus „Machine Learning“ etwas genauer an, so wird rasch klar, dass diejenigen, die wirtschaftlich von der Technologie profitieren, diesen Profit zu großen Teilen aus der kostenlosen Arbeit derjenigen extrahieren, die für den Erfolg mitverantwortlich sind, den Zusammenhang zwischen ihrer Arbeit und dem geschäftlichen Profit aber nicht erkennen, weil er ihnen vorenthalten oder zumindest nicht offensichtlich gezeigt wird. Nirgendwo wird man beim Ausfüllen eines Google Captchas darauf hingewiesen, das man eben Arbeit geleistet hat. Oder beim Korrigieren falsch erkannter Wörter in der automatischen Texterkennung.
Anbieter von auf Machine Learning basierenden Diensten verschweigen, dass das Training ihrer Programme in Wirklichkeit ganz gewöhnliche, wenn auch auf sehr viele Nutzer verteilte Arbeit ist. Wer schon einmal mit einem Google Captcha zu tun hatte, hat bereits kostenlos für Google gearbeitet. Google nutzt seine Captcha-Technologie, um von Menschen generierte Daten für seine lernfähigen Programme bereitzustellen. Ich als Nutzer trainiere also die Leistungsfähigkeit dieser Programme mit jedem Captcha, das ich löse1. Das hilft Google dabei, Texte zu digitalisieren, Bilder zu beschreiben, Scans zu analysieren, Google Maps zu verbessern oder seine Künstliche Intelligenz bei der Lösung von Problemen zu unterstützen – alles Produkte, die der Konzern direkt oder indirekt verkauft und damit Gewinne macht.
Aral Balkan hat schon recht, wenn er in diesem Kontext von People Farming spricht, denn wo auch immer von Machine Learning die Rede ist, handelt es sich bei genauerem Hinsehen um People Farming: Menschen trainieren ein Programm bewusst oder unbewusst, auf jeden Fall aber kostenlos. Dass das „Programm“ oder die „Maschine“ aber nur Werkzeug wirtschaftlichen Interesses ist, verschweigt der Terminus. Ja, selbst nur 2 Sekunden, die ich für das Lösen eines Captchas oder für das Ausbessern falsch erkannter Textstellen aufwende, sind und bleiben Arbeitszeit, für die ich nicht entlohnt werde. Wenn mein Tun aber zur Schaffung oder zur Verbesserung eines Produkts beiträgt, dann bin ich mit meiner Arbeitsleistung an diesem Produkt beteiligt. Es darf mir dann auch sauer aufstoßen, wenn das im Newsletter – schlimmer noch als bei Google! – durch die Wahl der Worte völlig verneint wird.
- Immerhin ist diese Information auch auf der Website für Googles reCaptcha-Programm zu finden – allerdings nur da! ↩